“Topic Modeling Detroit” seeks to perform a “distant reading” of public domain books about Detroit digitized by HathiTrust and available in the HathiTrust Research Center. While ultimately it would be ideal to bring this project into conversation with other work on representations of Detroit (e.g. Dora Apel’s recent book, Beautiful Terrible Ruins: Detroit and the Anxiety of Decline), this project is primarily exploratory and designed for me to familiarize myself with the textual analysis tools available through the HathiTrust Research Center. Most of my research (even libraryland research) relies on close reading and textual analysis, so it is helpful for me – and may be helpful for readers – to think of this project primarily in terms of revealing the sorts of texts that are in this particular HTRC corpus rather than in terms of making an argument about how Detroit is represented in pre-1963 texts.
Background & Process
The HathiTrust Research Center is available to universities that are members of the HathiTrust and is designed to “[enable] computational access for nonprofit and educational users to published works in the public domain.” What this means is that once you have created an account, you can create text corpora and then analyze those corpora with eleven different techniques SUPER EASILY. Francesca Giannetti has a very good primer on the HathiTrust Research Center, which also includes information about using the Data Capsule. The Data Capsule allows you to use in-copyright books, unlike the algorithms embedded in the HathiTrust Research Center.
Creating a workset was very easy, since I knew I wanted the items to have “Detroit” as a subject heading. Subject headings get at the topic of an item, unlike full-text searches (too broad) or title searches (too narrow). There are two interfaces for creating worksets (all images can be clicked on to embiggen):
The workset I created and used for analysis contained 2,364 books whose publication dates were prior to 1963. This is most likely because there are no public domain texts with later publication dates digitized by HathiTrust. In my initial conception of the project, I wanted to work with pre-1960 texts, so the fact that all of the texts in HTRC were published before 1963 is actually okay. The riots were in 1967 and the standard narrative around the decline (and ruination) of Detroit locates the beginning of that with the riots. Thomas Sugrue’s book, The Origins of the Urban Crisis, pushes the beginning of the depopulation of Detroit back to the mid-1950s. The early 1960s would be after depopulation has started but before the intense strife of the later 1960s, and therefore acts almost like a tipping or inflection point. I would eventually like to do something similar with texts after the riots – as far as I know, no one has done anything with textual corpora – but those are mostly in copyright and therefore not available in HTRC.
Although HathiTrust is very good about metadata like publication year, there were 244 titles whose publication date was indicated as 1800, but spot checking revealed that those dates are not entirely accurate. There were also 52 items with a publication date of “0000,” which is unpossible and 124 items with a publication date of “1000,” which seems unlikely. 2324 of the books were in English and 2248 were published in the United States. Each of these facets (there are a few others) can be used to limit your workset and each can be clicked on to see the list of items that have the selected characteristic.
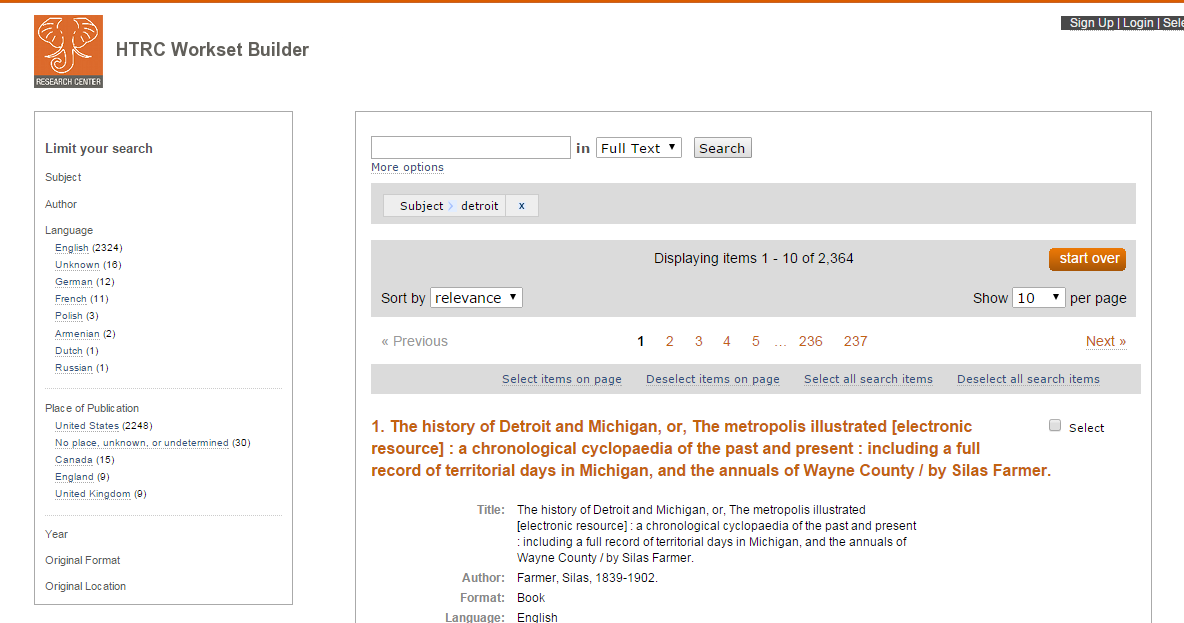

Each item record is connected to the full view and full catalog record of the item in HathiTrust.
The topic modeling algorithm within the HTRC uses Mallet and allows you to select the number of “tokens” (words) and topics. In this project, I mostly played around with varying numbers of both. Originally, I wanted to create topic models for specific date ranges, but the interface does not really allow it. Years have to be entered individually and joined by Boolean connectors. I actually did try this with texts from the 1950s and 1960s and my results were very similar to the results for the entire corpus. This corpus only consisted of 157 texts. I also decided not to limit by date range because so many texts lacked or had inaccurate publication dates. I do think incorporating date ranges would enhance the project, but it would involve a lot of data cleaning and possibly additional research into publication dates. I’m also not sure if cleaned data/additional data can be used within the HTRC (I suspect not, having poked around a fair amount). Running the algorithm involves two clicks, naming the job, and deciding on the number of tokens and topics. It does take a day or two to return the results, as far as I can tell, and they are displayed within the browser, like so:
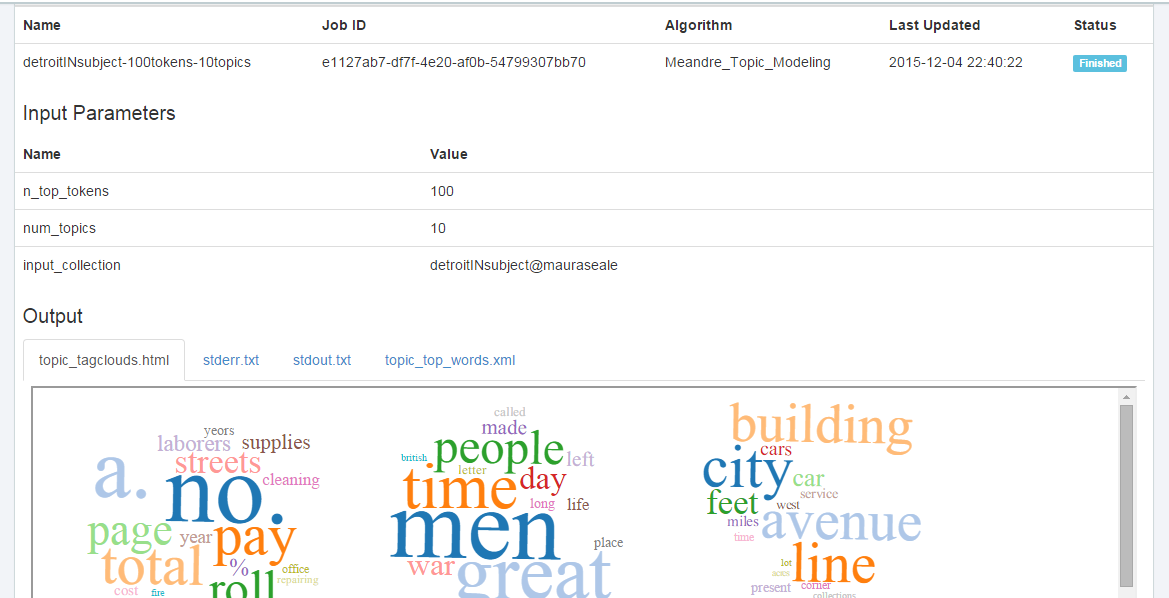
This means the word clouds are not able to be manipulated and the best way to capture them is with a screenshot. The corpus cannot be downloaded as a text or other file. The results page also includes a text list of the most popular words, but it is only a list and does not include word frequencies. This means that you cannot use and manipulate the data with another tool, which is a definite drawback.
I ran the topic modeling algorithm four times: 100 tokens/10 topics; 200 tokens/10 topics; 200 tokens/20 topics; 200 tokens/40 topics. Screenshots of the results for each run and an explanation of the screenshots are available on my first draft of this project. I want this final version to focus more on the topics themselves and I think the raw results clutter and confuse the matter.
Topics and Analysis
The topic models created with 100 tokens and 10 topics and 200 tokens and 10 topics seem to resemble each other and also to be the most coherent set of topics. These models clearly identify topics or genres within the corpus. They are:
- history
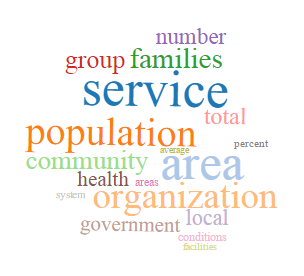
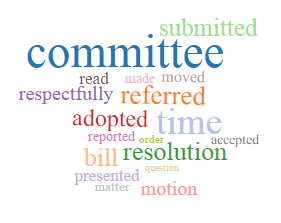
- city government/administration
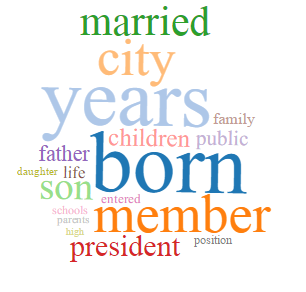
- biography
- education/schools
- geography/maps
These topics appear in each of the four runs, although the word clouds do differ between runs. Below is each of these topics with the associated word clouds from all four runs. The file names of the images indicate which run it is from (#tokens-#topics-topicname). I chose to include word clouds from all four runs because including all of them illustrates both the internal diversity and consistency of the topics. Most of these topics – history, city government/administration, education, geography – are refined in runs with more topics.
History

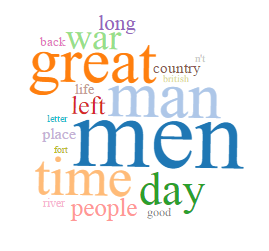


City Government/Administration





Biography



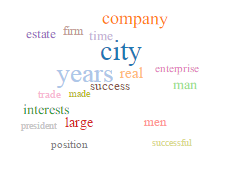


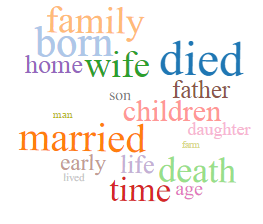


Education/Schools


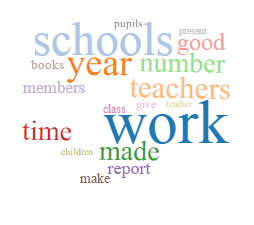








Geography/Maps




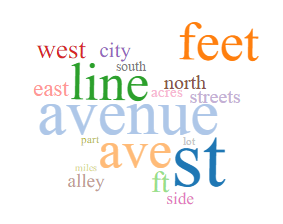

The topic model created with 200 tokens and 20 topics refines these categories somewhat and introduces related topics. The topics above are still present, and the word clouds for those topics are included above. Below are the word clouds for topics introduced in this run, which are:
- 18th/19th century history
- construction/building
- labor/employment
- medicine
- libraries
- accounting/budgets
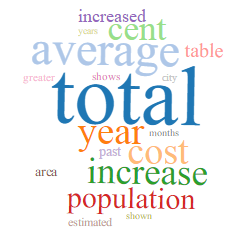
- population/demography
- cars
These are pretty interesting refinements/related topics (and we see the emergence of “cars,” which is of course what Detroit has been associated with throughout the twentieth century), but this topic model also introduces some noise. Two of the topics from this run are not meaningful and one is made up of symbols. I removed all three from this version of the project, but the two topics that contain words can be seen within the raw results section of the first draft.
Some of these topics also appear in the final run (200 tokens, 40 topics). These word clouds are included here and again, the file name of the images indicates which run it is from.
18th & 19th Century History
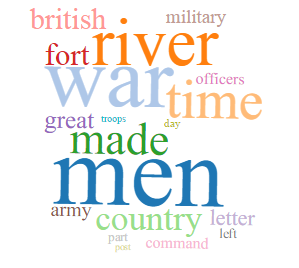

Construction/Building




Labor/Employment

Medicine

Libraries


Accounting

Population/Demography
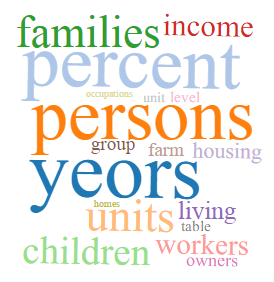
Cars


The topic model created with 200 tokens and 40 topics further refines the broad topics of the 10 and 20 topic models. It includes the following additional subtopics, which do not appear in any other runs:
- legal/court
- public works
- water
- books
- government documents
- engineering/math
- church
- car manufacturing
This topic model also reveals that some of the corpus is in French, although the words included in that topic are primarily stop words.
Legal/Court

Public Works


Water

Books

Government Documents


Engineering

Church

Car Manufacturing

French

Conclusion
When I initially reviewed the topic models produced in the four runs, I was a little disappointed, but putting together this analysis has actually revealed a lot about the texts in this corpus. I can tell that many of the texts are government documents of some sort, which makes sense given that the texts in HTRC are in the public domain, and that my analysis includes publication dates that are still in copyright. Many of the topics in addition to the specific government documents topic likely include government documents: accounting, legal/courts, education, public works, city administration, libraries, labor, population/demography, and possibly others.
When I was in graduate school, I analyzed newspaper articles and photographs published between 1990 and 2005 that depicted Detroit as ruined (I wrote about this ten years ago, when it wasn’t the subject of much critique, but now it is). This discourse is very much tied to the 1967 riots and downfall of the auto industry (including its move to overseas production facilities), so I did not expect to find evidence of this in this corpus, given that all of the texts were published before 1963. What I did know about Detroit prior to 1967 was its spectacular growth in both population and size (with the expansion of the auto industry, the Great Migration of both black and white Southerners, and during WWII as the “Arsenal of Democracy”), the emergence and expansion of both the auto industry and organized labor, and its long history as a port city, beginning with the French in 1701. The topics of the corpus pretty much reflect this history. Texts about government and infrastructure, geography and maps, and construction speak to the city’s growth and expansion. The corpus includes texts about cars, car manufacturing, and labor, although these are not as dominant as I might expect. Detroit’s early history also appears in the corpus. I did not expect biographical texts to be as prevalent as they are , but I suspect many are connected to Detroit’s early history. One aspect of Detroit’s history that is completely missing from these texts is race. This is not entirely surprising, given that even though race is central to the riots and ruins narrative and to Detroit’s postwar history (Sugrue is very good on this), it is also constantly erased or coded as something else.
Using the HathiTrust Research Center was very easy and I can now show students or faculty how to build a workset and use the analysis tools embedded within HTRC. There are a few drawbacks to using the HTRC, however, both specific to this project and more generally. Limiting to public domain texts means that only specific post-1924 texts are included, like government documents, which may overly influence the resulting topics. On the other hand, Detroit’s rapid expansion in terms of population and geography in the first half of the twentieth century is a story of the expansion of government and infrastructure, so in some ways the corpus is very representative. I’m particularly interested in the period between 1920 and 1960, and that period is not well-represented in HTRC, or really in any digitized text corpus. I’m also very interested in change over time, so the lack of good publication year metadata for so many of these texts was really disappointing. Cleaning the data is possible since some publication dates appear in titles or within the texts, but it doesn’t seem possible to add that data to the HTRC.
Now that I’m wrapping up this project, I do feel like I learned a lot about both topic modeling and some of the ways (not all!) Detroit was talked about before 1963. Using the HTRC was an easy way to familiarize myself with topic modeling, and to play around with other forms of analysis, like extracting geographic information. For projects involving late 19th and early 20th century texts, which HathiTrust has a lot of, this would be a great place to start exploring topic modeling. There are drawbacks, like being limited to the tools embedded in the platform, but the ease of using the HTRC balances that out. There are also drawbacks in terms of the available texts for a project like this one, but performing the topic modeling revealed both those drawbacks and other possibilities.
And just because it’s one of my favorite texts about Detroit: Design for Dreaming.