REVISED 12/6/15
[This is a draft/outline version of my final project, which uses topic modeling to analyze public domain books about Detroit in the HathiTrust Research Center.]
“Topic Modeling Detroit” seeks to perform a “distant reading” of public domain books about Detroit digitized by HathiTrust and available in the HathiTrust Research Center. While ultimately it would be ideal to bring this project into conversation with other work on representations of Detroit, this project is primarily exploratory and designed for me to familiarize myself with the textual analysis tools available through the HathiTrust Research Center.
The HathiTrust Research Center is available to universities that are members of the HathiTrust and is designed to “[enable] computational access for nonprofit and educational users to published works in the public domain.” What this means is that once you have created an account, you can create text corpora and then analyze those corpora with eleven different techniques SUPER EASILY. Francesca Giannetti has a very good primer on the HathiTrust Research Center, which also includes information about using the Data Capsule. The Data Capsule allows you to use in-copyright books, unlike the algorithms embedded in the HathiTrust Research Center.
Creating a workset was very easy, since I knew I wanted the items to have “Detroit” as a subject heading. Subject headings get at the topic of an item, unlike full-text searches (too broad) or title searches (too narrow). There are two interfaces for creating worksets (all images can be clicked on to embiggen):
The workset I created and used for analysis contained 2,364 books whose publication dates were prior to 1963. Although HathiTrust is very good about metadata like publication year, there were 244 titles whose publication date was indicated 1800, but spot checking indicates that that date is not entirely accurate. There were also 52 items with a publication date of “0000,” which is unpossible and 124 items with a publication date of “1000,” which seems unlikely. 2324 of the books were in English and 2248 were published in the United States. Each of these facets (there are a few others) can be used to limit your workset and each can be clicked on to see the list of items that have the selected characteristic.

Each item record is connected to the full view and full catalog record of the item in HathiTrust.
The topic modeling algorithm within the HTRC uses Mallet and allows you to select the number of “tokens” (words) and topics. In this project, I mostly played around with varying numbers of both, rather than limiting by years as I initially thought I might. As I mentioned earlier, the publication dates are incorrect for many items and it’s not possible to limit your search to a date range (years have to be entered individually and joined by Boolean connectors). Running the algorithm involves two clicks, naming the job, and deciding on the number of tokens and topics. It does take a day or two to return the results, as far as I can tell, and they are displayed within the browser, like so:
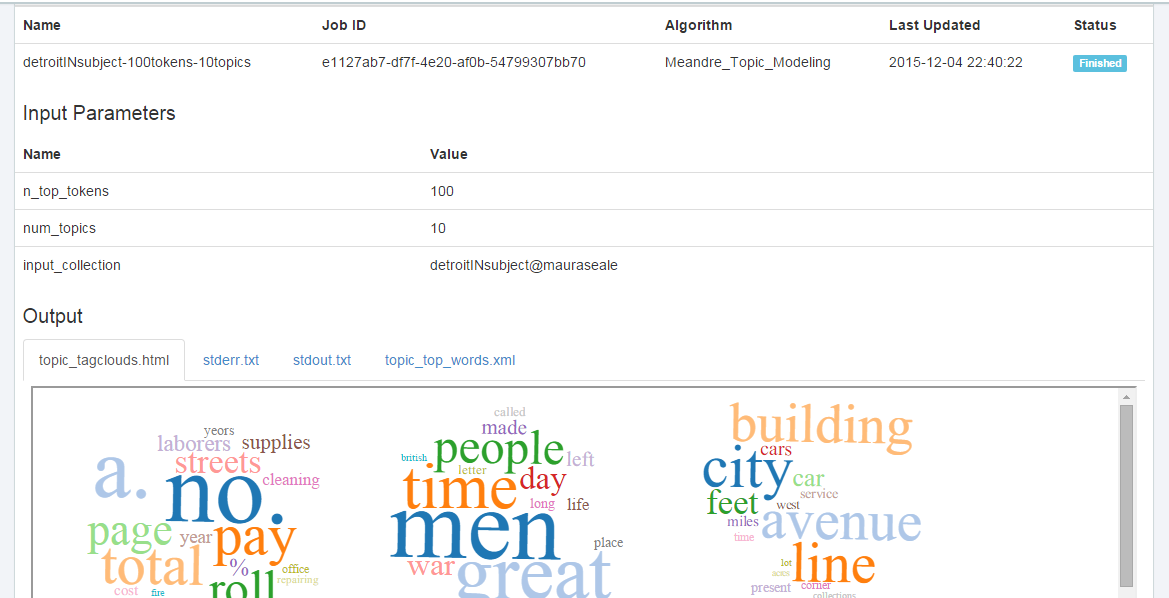
This means the word clouds are not able to be manipulated and the best way to capture them is with a screenshot. The results page also includes a text list of the most popular words.
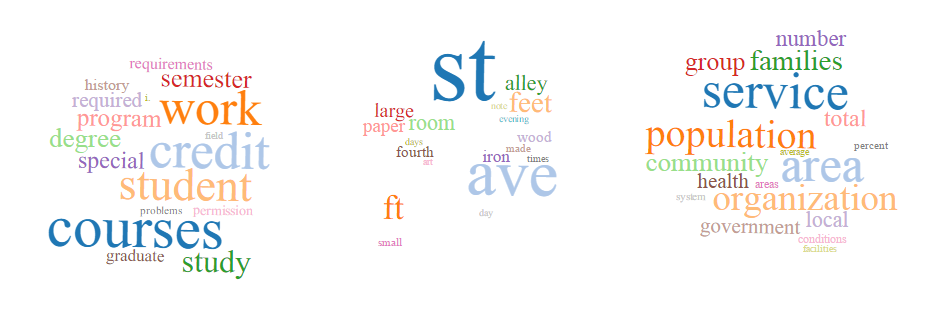
I ran the topic modeling algorithm four times: 100 tokens/10 topics; 200 tokens/10 topics; 200 tokens/20 topics; 200 tokens/40 topics. Screenshots of the results for each run are below and include between one and three topics. This is due to the total number of topics and the way they are displayed on the results page. Differences in size between topics should be ignored, since the topics are the same size on the results page (that is, I just took screenshots and didn’t resize them). Also, each set of results had at least one topic that consisted of punctuation marks, diacritics, symbols, and other non-word content. I did not include those here.
100 tokens/10 topics

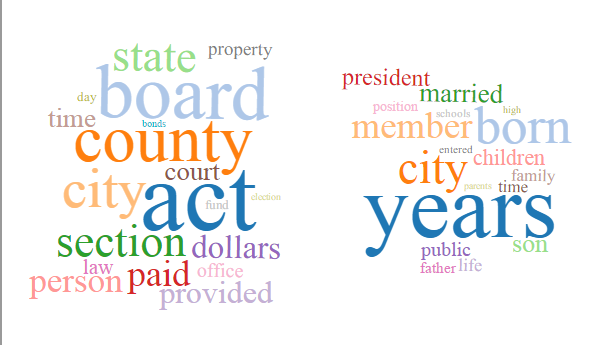

200 tokens/10 topics



200 tokens/20 topics
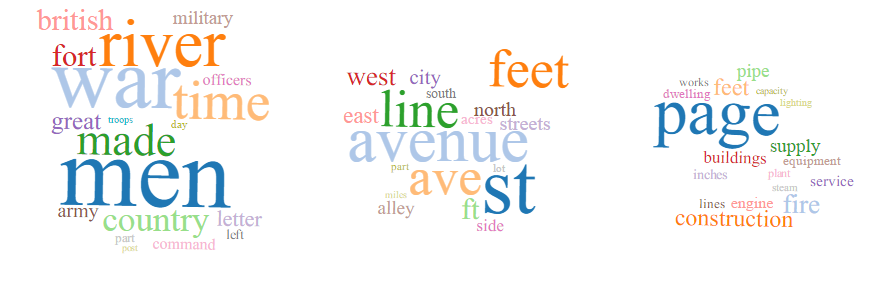



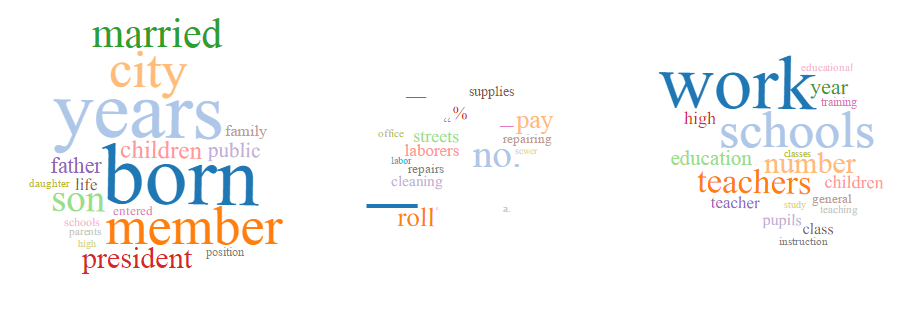
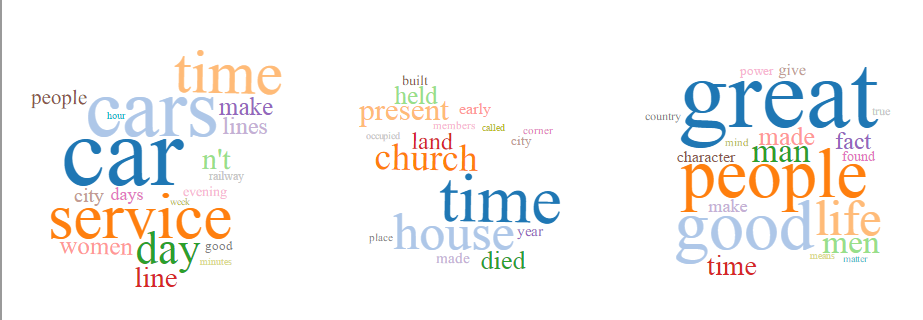

200 tokens/40 topics




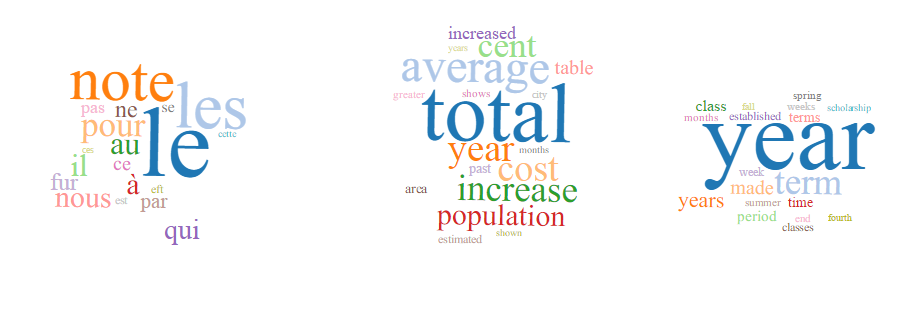









Analysis
The topic models created with 100 tokens and 10 topics and 200 tokens and 10 topics seem to resemble each other and also to be the most coherent set of topics. These models clearly identify topics or genres within the corpus. They are:
- history
- city government/administration/development/public projects
- biography
- education/schools
- geography/maps
The topic model created with 200 tokens and 20 topics refines these categories somewhat and introduces related topics. The topics above are still present
- 18th/19th century history
- construction/building
- medicine
- libraries
- accounting/budgets
- cars
These are pretty interesting refinements/related topics (and we see the emergence of “cars,” which is of course what Detroit has been associated with throughout the twentieth century), but this topic model also introduces some noise. Two of the topics above are not meaningful, and I removed one consisting of symbols.
The topic model created with 200 tokens and 40 topics further refines the broad topics of the 10 topic models. It includes the following additional subtopics:
- legal profession/court
- public works
- water
- population/demography
- books
- government documents
- engineering/math
- church
- car manufacturing
This topic model also reveals that some of the corpus is in French, although the words included in that topic are primarily stop words.
When I initially reviewed the four topic models, I was kind of disappointed, but in taking another look, they do reveal a fair amount about the items in the corpus, particularly the broad categories they fall into. Compared to a content analysis I did of newspaper articles about Detroit, this is obviously much broader and less detailed, but it could definitely help identify subsets of texts to engage in close reading. Using the HathiTrust Research Center was very easy and I can now show students or faculty how to build a workset and use the analysis tools embedded within HTRC. There are a few drawbacks, however, both specific to this project and more generally. Limiting to public domain texts means that only specific post-1924 texts are included, like government documents, which may overly influence the resulting topics. This is particularly significant with the subject of this specific project, which only really became significant in the twentieth century (I’m particularly interested in the period between 1920 and 1960, and that period is not well-represented in HTRC, or really in any digitized text corpus). I’m also very interested in change over time, so the lack of good publication year metadata for so many of these texts was really disappointing. I had hoped to be able to perhaps look at individual decades, even with the caveat I just mentioned. This could be addressed by manually looking at the catalog records for texts with years of 1000 or 0000, since for at least some of them, the publication date is in the title or text. This would be extremely time-consuming, though, and for uncertain results.